Icebreaker Performance
Get the flexibility of an open data lake with the speed of a proprietary warehouse.
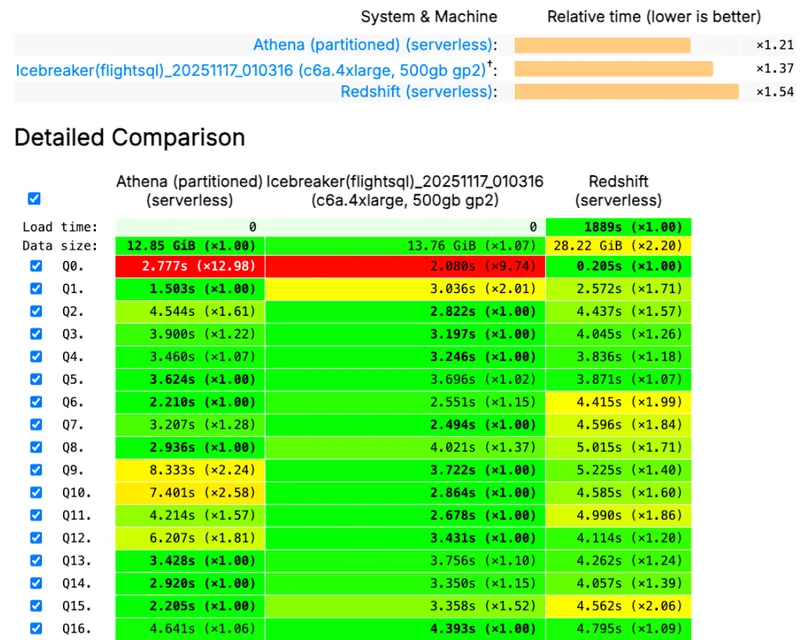
Performance Metrics
There are two ways to get excellent performance: (1) move all your data into a proprietary system that you can't control or (2) over-size and over-provision a system that you can control. Both are terribly expensive.
Icebreaker offers a third way: a serverless query platform for your data lake that gives you control over:
- your budget
- performance expectations (SLAs)
- preferred resources (negotiated compute)
Icebreaker automates the rest, with performance comparable to what you need and expect.
Performance Accelerators
Far beyond the separation of storage and compute, Icebreaker disaggregates compute to a unit-level, on-demand model.
- Zero-Copy Execution: Icebreaker interfaces directly with your Apache Iceberg metadata to pull only the required partitions into ephemeral pods.
- Controlled Scalability: You configure Icebreaker with budgets and whether to use Spot and negotiated compute pricing. Icebreaker automatically scales up, shuts down, throttles, and pre-empts queries based on your priorities.
- Multi-Level Caching: During query planning, Iceberg metadata instantly validates the cache. Icebreaker can even pull partial results from cache and the rest from a live query, dramatically reducing time-to-answer.
- Columnar, vectorized execution: Our embedded DataFusion query engine delivers exceptional analytic query performance.